Vectorising David
Part of the original draft I have written for the book Prompt

This article is part of the original draft I have written for the book Prompt with my friend David Boyle. Touch lightly on transformer architecture and how tokeniser work.
12 min read
A very brief intro in case the whole article is too long to read:
Think about words in Bytes, a bunch of 0 and 1. If you get the impression that AI is all about probabilities–you are not wrong. ChatGPT uses a bunch of 0 and 1, encoded from words within sentences, as input and a huge vocabulary dictionary. It didn’t generate a whole block of text for you; it was “thinking” the best next word while generating every word. In a nutshell, this is how GPT-like models output in the simplest form:
- This (First words and then what’s the next most possible word?)
- This book (High probability as it is closer to the prompt)
- This book talks (High probability a verb appears after a noun)
- This book talks about
- This book talks about artificial
- This book talks about artificial intelligence
- This book talks about artificial intelligence in
- This book talks about artificial intelligence in marketing
- This book talks about artificial intelligence in marketing.
Every time it generates a word, it looks for the next most possible word to pair with the previous one. OpenAI hired 40 data trainers / human labellers to generate training data and give feedback on the results. Then it iterates this process with more prompts, data, and feedback.
Context: Beyond the pattern of a sentence
One of the most common natural language processing applications is at our fingertips: every time we type in something on our phone it suggests the next word.
In earlier NLP models, say 2003, it treats words with static values. The context of “south” within “Something went south.” and “I live in the south bank.” has no difference. People created a rule-based structure–using cues, such as negation to help NLP models perform better in linguistic tasks in 2012. It was quickly revoked because it draws technical limitations — how big can this cue dictionary go? Based on the technical limitation we can already infer that the model won’t be able to understand context, nor achieve more complex linguistic tasks (ex: your prompt has several lines of text and include conflicting cues).
Source: Example of false negation cues from UCM-I: A Rule-based Syntactic Approach for Resolving the Scope of Negation
Context is important.
Take an example if someone posted on Twitter at 7:35 am:
“ Thanks for coming in today, coach.”
It sounded like sheer appreciation. But if he also tweeted at 6:09 am saying,
“Omg it’s snowing right now, and our class is supposed to start at 6 am! The coach is almost 10 minutes late!!! How can she just let us stand in the snow and wait? Shall we just leave like the teacher didn’t show up?!”
Then we have an idea that he is probably being sarcastic about the coach being late. But breaking the two sentences separately, we have very little idea about what he was referring to or what it actually means. We will return to this “context” problem a bit because we have another problem before going into some state-of-the-art neural network. And to be very honest, any neural network is just matrix multiplication. We tried to write them in plain English. Secondary school level maths is enough. If you are not happy, we have also linked to multiple resources so you can check them up — as always :)
Matrices are rows of vectors(or numbers, but here we refer to vectors because they have to represent length and position later on). And matrix multiplications are rows of vectors multiplied by rows of vectors. Vectors are objects with certain properties. It has both a magnitude and direction.
Actually, we have a big Problem: Computers can’t understand text but numbers, so how are languages being processed?
Tokenizers: Translator between machine and human
A high-performance, high-functional tokenizer is essential in a machine-learning system focusing on NLP tasks. Because your users don’t want to wait as soon as they hit enter. In production, time is calculated in milliseconds. The longer they wait, the more likely they will leave the site with bad reviews. And that happened on a lot of generative AI applications.
Converting words into plain binary form is not enough. The objective of a tokenizer is simple: find the most meaningful, relevant way to represent texts by numbers. It splits text into words or subwords; then words are converted to ids through a look-up table. And there are multiple tokenization algorithms. The sentence “David decided to write a book.” can be converted to
[“David”, “decided”, “to”, “write”, “ a”, “book”, “.”] to get
[(“David”,15), (“decided”20), (“to”, 5), (“write”,10), (“ a”,3), ( “book”,8), ( “.”, 1)]
or character-based like [“D”, “a”, “v”,…. “o”, “k”, “.”].
The former requires a huge vocabulary bank, a lot of memory and time to consume large text. Character-based tokenization is relatively easy and saves a lot of memory(less vocabulary!) and time. Still, it is harder for the model to learn the actual pattern of a language. In production and actual training, it results in serious performance loss.
Take an example: Say you make a search engine and train the model with a character-based method, and you set a fuzzy search where that anything that matches 30% would count towards a related search result. I went on to search “ChatGPT Prompt” and on top of my search results could be “Progressive Web App” and “Chat with Putin”. Earlier NLP models used it, and the result was a joke.
To improve model performance, models nowadays use a hybrid approach between word-level and character-level methods called subword tokenization. There are several of them; BERT uses WordPiece and ChatGPT uses Byte-level Byte-Pair Encoding. The wording is irrelevant; think about how you refactor a function like this:
24x⁴ + 8x³ + 12x² = y → Refactored → 4x²(6x²+2x+3) = y
[“David found his id card on top of his wounds.”] will be broken down into
[“Dav”, “id”, “f”, “ound”, “his”, “id”, “card”, “on”, “top”, “of”, “his”, “w”, “ound”, “s”.]
Mathematically they are similar. Byte-level Byte-Pair Encoding is a very clever method in all the tokenization algorithms(they are usually pretrained too). It refactored the most frequent character pair and provided the most frequent pair with relevant values. It also forces the base vocabulary to be 256 with additional rules to deal with punctuation/spacing in a sentence. Within the vocabulary of 50,257, each corresponds to the 256-byte base tokens, a special end-of-text token and the symbols learned with 50,000 merges. You can try to “tokenize” something yourself at OpenAI’s tokenizing tool.
Now the gap between humans and machines is sorted. How shall we solve the context problem?
Attention is all you need: The science of context and transformer architecture
Researchers were scratching their heads to find what could be the best solution for the next generation neural network — a model doesn’t just do a dummy job–prompting a simple sentence and outputting something silly; something avoids vanishing or exploding gradient problems; something can take a sequence as input and give a sequence as output; something has longer memory; a model saves computation cost and able to be trained with a relatively smaller amount of text.
Basically, they were looking for god.
Bag-of-words, gone. Recurrent neural networks, gone. Long Short-Term Memory, gone. For all the reasons listed above.
To address the context problem and issues that occurred in other models, a bunch of researchers from Google Brain (some of them work in OpenAI now!) dropped a bombing article, Attention is all you need in 2017, which is still at the forefront of any headlines of NLP models that shatters performance benchmarks. It brought a model that worked like a human brain(close to, but not enough) and accidentally changed computer vision, image generation and audio processing. But the strongest use cases were still in NLP: GPT and BERT. Both have a lot of variations in handling different tasks, and the model proposed in the original paper has evolved since.
Human vision systems inspired the attention mechanism proposed in the article.
Imagine how your brain processes when you see something. Say you walk into a restaurant during Christmas; you’d pay attention to the most stunning element, the Christmas Tree, the pretty waitress holding the menu waiting for you to take you to the seat, and then the seats scattered around the restaurant. You’d ignore insignificant details like the material of the floor, other customers in the restaurant or dimmed lights at the ceiling because they came off as irrelevant.
Same as the attention mechanism. It focuses on the most relevant parts in a whole block of text and anything relevant but ignores the insignificant details. Supporting the attention mechanism, they introduced a neural network called the Transformer which came with an encoder-decoder architecture. In a nutshell, an encoder is the part that deals with input pre-processing, and the decoder deals with output pre-processing.
Source: Michael Phi, Illustrated Guide to transformers step by step explanation
Like every data science project, there is a lot of preprocessing before the actual work.
Preprocessing 🤯
The first step is input encoding. We have mentioned tokenizers before. It will convert “David” into numbers first (I am using one-hot encoding here because it makes much sense since you are aware computers work with binaries, but it is a bad choice if you come across someone using it. ) at a vector size of 50,257.
Figure 29. Input encoding
GPT’s input sequence is defaulted to 2,048 words. And yeah we do that with every word. GPT-like models generally take the input and guess the next best possible output.
Input and Output sequences
And both input and output default to 2,048 words.
So we have a matrix of 2,048 x 50,257 and end up with a bunch of zeros and ones.
Matrix encoding
Wait a minute, GPT-3 uses Byte-level BPE, so the output will look like the below before it was cut down to zero and ones.
[11006, 3066, 284, 3551, 257]
Make something shorter. Something not 50,257. Also this is a really short sentence, so where are the rest of the 2,043 words? They are filled in with empty values, and the encoder is told to ignore them (a process called masking; otherwise the empty value will influence the whole sentence and the model can’t pay attention to important things).
But there are still many vectors to deal with for longer sentences, and we know they force the base vocabulary to be zero and ones. So there are a lot of empty spaces and wasted storage.
To solve this, we use an embedding function: a function takes the long vector of zeros and ones and then outputs an n-length vector of numbers like so. (Word Embedding, the process of mapping words to real vectors)
An embedding function in action
And then store them in a smaller dimension space (if the vector length is 2, it will be stored in a 2-dimensional space like x-y axis ones)
Words in a dimension space
But yeah, GPT’s dimension is much larger than two after multiplication between matrices: 12288 dimensions. ( A lot larger than the original paper which only has 512)
The first matrix below is a 2,048 x 50,257 sequence-encoding matrix.
The second matrix is a 50,257 x 122,88 embedding-weight matrix(learnt by model).
Figure 35. Matrix multiplication
Multiply both of them we get a 2,048 x 12,288 sequence-embedding matrix, and every word is represented by numbers on a “look-up table” for the model to look at. Awesome, everything is represented by numbers now. But so far we have no information on the absolute or relative position or the words(or token if you might call it).
So we do some positional encoding to give every word a position id to notify the model of each word’s position in the text before going into the multi-head attention layer (check the link if you are interested in the related literature, maths and python code).
Encoder and Decoder
Encoder and Decoder
Oh geez, that was a hell lot of preprocessing; it’s time to get some exciting work done. You can crunch on this baby graph or go back to 4 pages before and look at the bigger transformer architecture picture. What do they do? The encoder on the left maps an input sequence of text representations to a sequence of continuous representations.
The decoder on the right generated an output sequence of symbols one element at a time. At each step the model is auto-regressive and consumes the previously generated text as additional input when generating the next. Like what we said before (Imagine the turtle in Zootopia spilling out words one by one, but much faster)And the transformer allows this overall architecture using stacked self-attention, point-wise, fully connected layers to both the encoder and decoder. To clear some terms in case you get confused.
Stacked self-attention: A self-attention module takes x input and x output, is the mechanism to allow the input to interact with each other(“self”) and find out who they should pay more attention to (“attention”) and aggregates these interactions and attention scores as output. Stacked simply means: multiple times/layers.
To clear out how this works. Consider a sentence: David decided to write a book about ChatGPT because it is revolutionary.
Attention head
Transformer doubled down the idea of attention and packed together individual attention elements known as the “attention head” to “focus” on a word. It can tell the model how relevant or important that word is to understand the current word being parsed. Like the figure above we “focused” on [“write”] and its relationship with others.
The model learns three linear projections when the text goes through it(some trigonometry functions): “Queries(denoted as Q)”, “Keys(denoted as K)” and “Values(denoted as V)” and GPT-3 repeat this process for 96 times to create multi-head attention, each with a different learnt query, key, value projection weights.
Attention function
More attention head(multi-head attention) in one layer means the model can look back or forward in long text.
Our sample text was too short to have a beautiful graph so I grabbed this to help you see how beautiful it is with multi-head attention:
Source: Review — Attention is all you need
And the results of each attention head are concatenated together yielding a 2048x12288 matrix, which is then multiplied with a linear projection (which doesn’t change the matrix shape).
Point-wise fully connected layer: Means all connections between neurons(they are just numbers, in this case, there are several ones behind the dot like 0.00000012) have a fixed weight of 1(they all add up to 1) which means the output of each neuron in the previous layer is passed through to the next layer without any modification. This method allows the model to improve performance(without neglecting words).
And more layers of attention mean that your model can then learn a higher level of both syntactic structures and potentially, semantic meaning. The table below shows a dummy example of what the output for the word “write” from the attention layer might look like by multiplying different weight matrices together and each of them obtaining a weight to try and identify which words in the sentence the network should “pay attention” if they are important in the context.
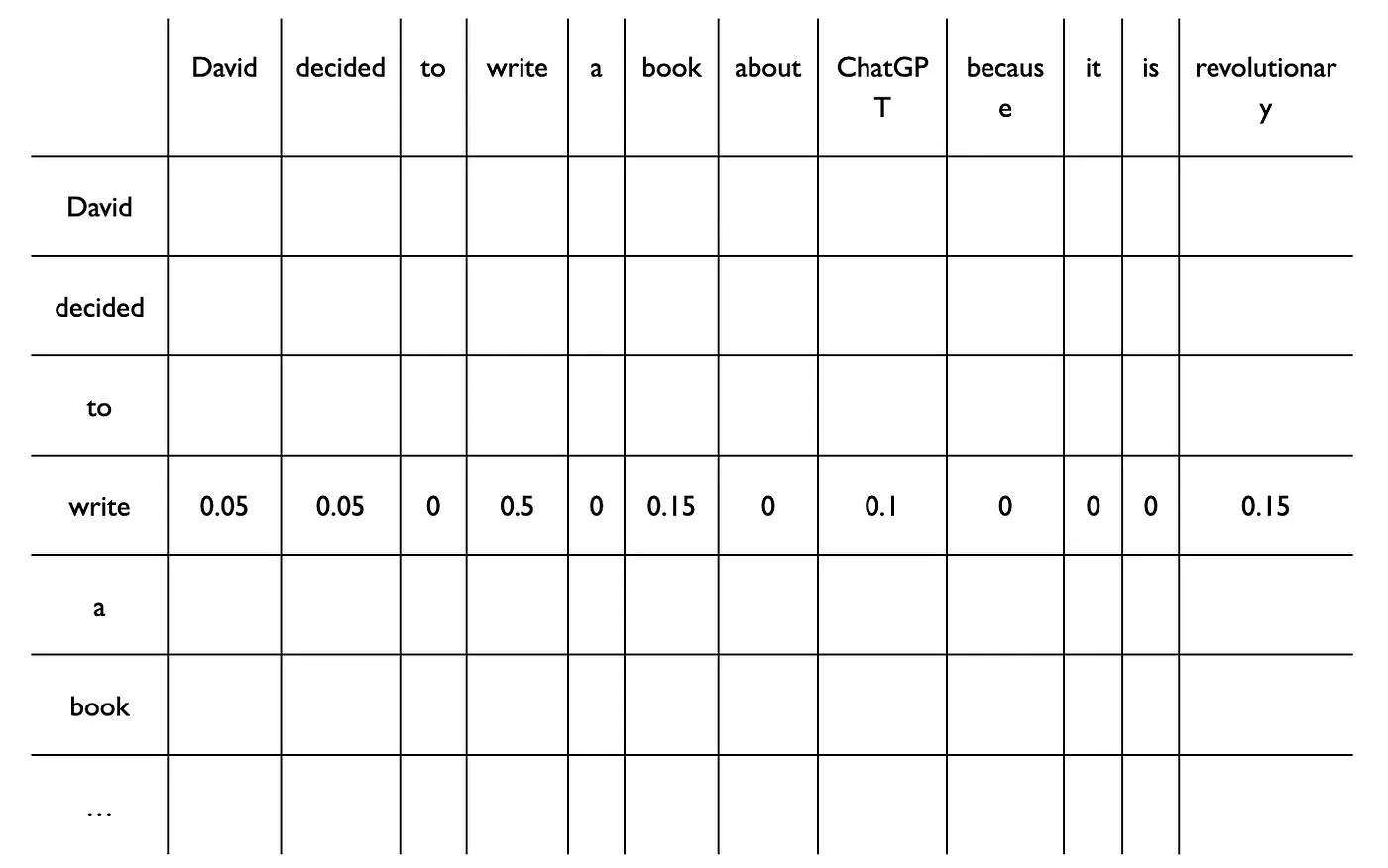
Finally we tackled the context problem. BERT-like models and GPT-like models both use the attention mechanism of the transformer architecture to learn context from text.
And by learning context, potentially, these models can develop some level of language skill (how they function is closer to the human brain after all! Note that I used “closer”, not “close”. We still have a long way to go until we reach a place where models I’m work like the brain.) which enables them to perform better on a range of language tasks(answering questions, summarising etc.).
After every output we get a matrix of 2,048x12,288! Huge! Now we just need to reverse engineer the work embedding process and map the data back to text. After all, we spent a hell lot of time learning it!! Also GPT uses the parameter top-k to limit the output, so it always picks the most likely words to make it grammatically correct — seeing something not true? Don’t get surprised.
Another thing: GPT-3, the base model of ChatGPT, uses sparse attention, allowing more efficient computation. So you see, these guys designed the whole architecture, everything with speed in mind.
That was long 🫠 And I still have a load in reinforcement learning with human feedback left in my draft.
Until next time 🫡